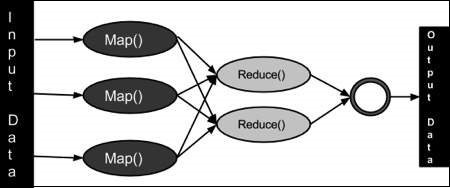
MapReduce
To take the advantage of parallel processing of Hadoop, the query
must be in MapReduce form. The MapReduce is a paradigm which has two
phases, the mapper phase and the reducer phase. In the Mapper the input
is given in the form of key value pair. The output of the mapper is fed
to the reducer as input. The reducer runs only after the mapper is over.
The reducer too takes input in key value format and the output of
reducer is final output.
Steps in Map Reduce
- Map takes a data in the form of pairs and returns a list of <key, value> pairs. The keys will not be unique in this case.
- Using the output of Map, sort and shuffle are applied by the Hadoop
architecture. This sort and shuffle acts on these list of <key,
value> pairs and sends out unique keys and a list of values
associated with this unique key <key, list(values)>.
- Output of sort and shuffle will be sent to reducer phase. Reducer
will perform a defined function on list of values for unique keys and
Final output will<key, value> will be stored/displayed.
How Many Maps
The size of data to be processed decides the number of maps required.
For example, we have 1000 MB data and block size is 64 MB then we need
16 mappers.
Sort and Shuffle
The sort and shuffle occur on the output of mapper and before the
reducer.When the mapper task is complete, the results are sorted by key,
partitioned if there are multiple reducers, and then written to
disk.Using the input from each mapper <k2,v2> , we collect all the
values for each unique key k2. This output from the shuffle phase in
the form of <k2,list(v2)> is sent as input to reducer phase.
The Algorithm
- Generally MapReduce paradigm is based on sending the computer to where the data resides!
- MapReduce program executes in three stages, namely map stage, shuffle stage, and reduce stage.
- Map stage : The map or mapper’s job is to process the
input data. Generally the input data is in the form of file or directory
and is stored in the Hadoop file system (HDFS). The input file is
passed to the mapper function line by line. The mapper processes the
data and creates several small chunks of data.
- Reduce stage : This stage is the combination of the Shuffle stage and the Reduce
stage. The Reducer’s job is to process the data that comes from the
mapper. After processing, it produces a new set of output, which will be
stored in the HDFS.
- During a MapReduce job, Hadoop sends the Map and Reduce tasks to the appropriate servers in the cluster.
- The framework manages all the details of data-passing such as
issuing tasks, verifying task completion, and copying data around the
cluster between the nodes.
- Most of the computing takes place on nodes with data on local disks that reduces the network traffic.
- After completion of the given tasks, the cluster collects and
reduces the data to form an appropriate result, and sends it back to the
Hadoop server.
Inputs and Outputs (Java Perspective)
The MapReduce framework operates on <key, value> pairs, that
is, the framework views the input to the job as a set of <key,
value> pairs and produces a set of <key, value> pairs as the
output of the job, conceivably of different types.
The key and the value classes should be in serialized manner by the
framework and hence, need to implement the Writable interface.
Additionally, the key classes have to implement the Writable-Comparable
interface to facilitate sorting by the framework. Input and Output types
of a MapReduce job: (Input) <k1, v1> -> map -> <k2,
v2>-> reduce -> <k3, v3>(Output).
|
Input |
Output |
| Map |
<k1, v1> |
list (<k2, v2>) |
| Reduce |
<k2, list(v2)> |
list (<k3, v3>) |
Terminology
- PayLoad - Applications implement the Map and the Reduce functions, and form the core of the job.
- Mapper - Mapper maps the input key/value pairs to a set of intermediate key/value pair.
- NamedNode - Node that manages the Hadoop Distributed File System (HDFS).
- DataNode - Node where data is presented in advance before any processing takes place.
- MasterNode - Node where JobTracker runs and which accepts job requests from clients.
- SlaveNode - Node where Map and Reduce program runs.
- JobTracker - Schedules jobs and tracks the assign jobs to Task tracker.
- Task Tracker - Tracks the task and reports status to JobTracker.
- Job - A program is an execution of a Mapper and Reducer across a dataset.
- Task - An execution of a Mapper or a Reducer on a slice of data.
- Task Attempt - A particular instance of an attempt to execute a task on a SlaveNode.

0 comments:
Post a Comment